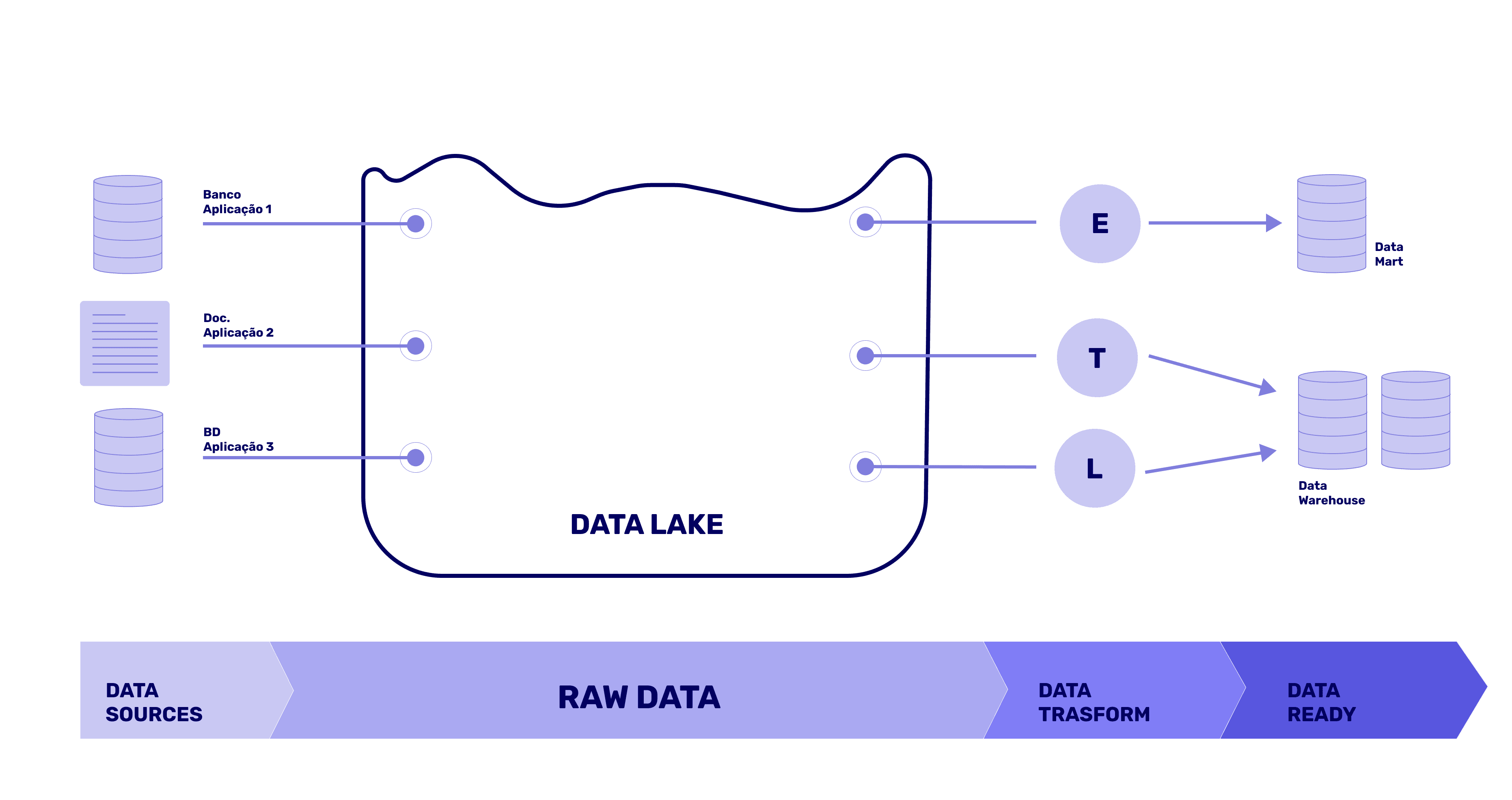
O Data Lake é um repositório de dados heterogêneo, ou seja, é possível armazenar tabelas não relacionais e relacionais, documentos, dados estruturados (tabelas e banco de dados), semiestruturado (páginas web) e não estruturado (imagens e áudios – schemaless). Os dados são mantidos em seu estado bruto e processados em sua complexidade e tamanho, quando necessário. Normalmente, esse repositório é centralizado e baseado em nuvem por questões de escalabilidade e segurança.
Por que pensar em Data Lake?
Na atualidade, o volume e fontes de dados diversificaram e cresceram muito, tanto pela conectividade e pelos IOTs, quando pelo acesso a tecnologia na sistematização dos processos de trabalho e pela experiência aprimorada e centralizada no consumidor. Isso posto, as estruturas tradicionais passaram a ser ineficazes no armazenamento e acesso aos dados. Para contornar esse cenário de forma segura e eficaz, os Data Lakes começaram a ser implementados pelas organizações.
Empresas que aderem ao Data Lake tendem a ganhar uma vantagem competitiva com seus concorrentes: pela possibilidade de processar os dados em seu formato original oriundos de diferentes fontes; permitindo uma visão de negócio ampliada e diversa; identificando padrões de comportamento de clientes; aumentando a produtividade e tomada de decisão com informações personalizadas para cada estratégia, além, claro, de crescer a empresa.
Falar de Data Lake pode trazer um questionamento pela semelhança e para quem é familiarizado com Data Warehouse, apesar de terem estruturas distintas. A seguir, falaremos melhor sobre essas duas possibilidades de armazenamento e análise de dados.
Qual a diferença em um Data Lake e um Data Warehouse?
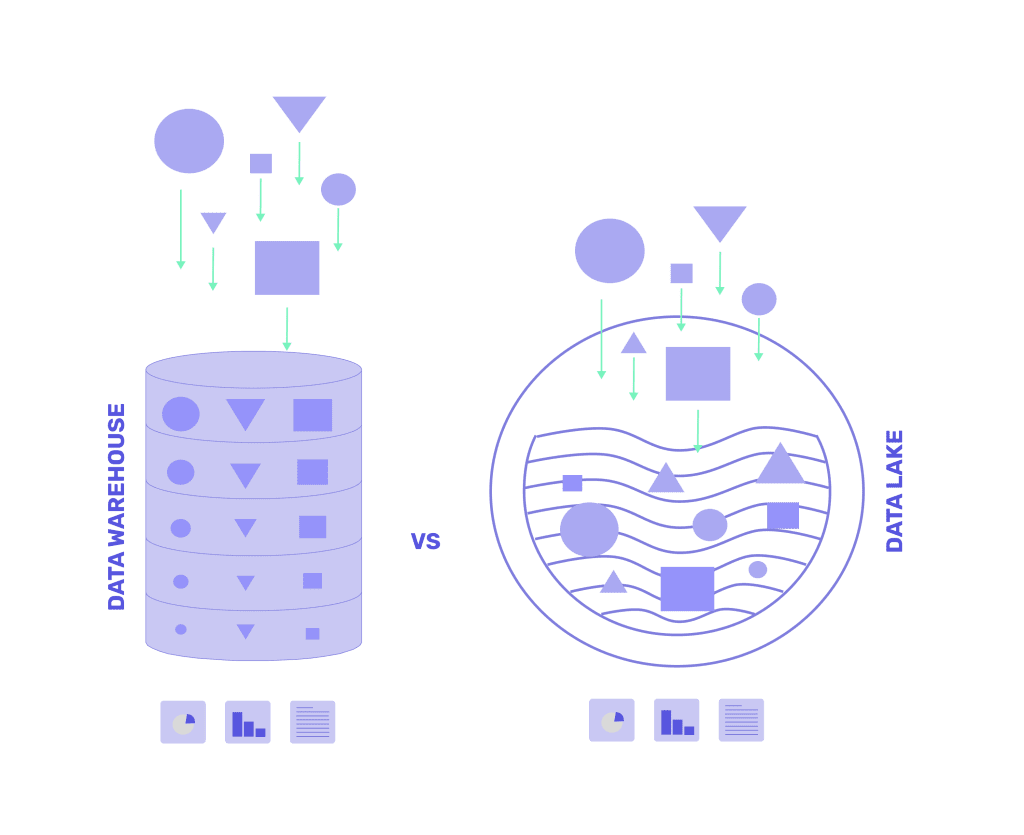
Para entender as diferenciações entre as estruturas é importante conhecer dois conceitos:
Schema-on-read: O esquema é definido e imposto ao dado no momento da leitura, propiciando que o mesmo dado em sua forma bruta possa ser utilizado em diferentes aplicações sem prejuízos a informação.
Schema-on-write: O dado obrigatoriamente deve seguir o esquema estrutural no momento da sua escrita na base de dados, propiciando uma estrutura pré-formatada a ser compreendida na reutilização dos dados e proporcionando flexibilidade e maior velocidade do armazenamento e geração de dados, respectivamente.
Assim sendo, compreendemos que o data lake é schema-on-read enquanto um data warehouse utiliza o conceito de uma estrutura pré-definida, isto é, schema-on-write.
O data Warehouse é um armazenamento de dados relacionais com estrutura schema-on-write, filtrados e transformados para trazer dados precisos em consultas específicas em SQL e gerar relatórios ricos e confiáveis para tomadas de decisões. Diferente desse cenário, o Data Lake, que possui estrutura de dados schema-on-read, os dados são armazenados sem a preocupação de uma limpeza e estruturação, não pensando nas perguntas que devem ser respondidas em seu negócio no momento da captura deles.
Duas práticas importantes de serem adotadas ao escolher um Data Lake
Como o Data Lake armazena dados de fontes distintas e de diferentes formatos, é recomendado construir um catálogo de dados. Essa estrutura documentará o ambiente e facilitará a consulta das informações. Desta forma, diferentes profissionais da empresa podem acessar os dados de forma direta, até mesmo sem utilizar um programa de análise externo.
Os dados são de extrema sensibilidade e fazem parte de uma camada crítica das organizações, sendo assim, é imprescindível o provisionamento de uma camada de segurança robusta e compatível com o nível de criticidade dos dados, além de camadas de monitoramento e otimização de desempenho.
Qual a aplicabilidade de um data lake?
É importante avaliar a quantidade e complexidade dos dados capturados pelo seu negócio, quais as finalidades pretendidas com esses dados, a segurança, gerenciamento e ferramentas de processamento deles. Como o Data Lake funciona não só como um armazenamento de dados mas também como uma fonte de conhecimento intrínseco da companhia, essa funcionalidade traz redução de custo de propriedade, acelera análises, melhora a segurança e trabalha em conjunto com a machine learnig e IA.
Diferentes nichos de negócios podem adotar o data lake como estratégia e aumentar o potencial de inovação e resultado. Empresas de finanças, por exemplo, podem capturar e armazenar dados do mercado em tempo real a fim de obter uma carteira mais eficiente. Podemos citar também o nicho de saúde, nossa principal categoria de clientes, que podem usar dados para aperfeiçoar a qualidade do sistema de saúde, eficiência no atendimento médico com acesso ao histórico do paciente e redução de custo e espera por soluções adequadas.
Esses são apenas alguns exemplos de como o Data Lake pode potencializar empresas através de dados, algo tão valioso na atualidade. É importante ter um profissional de tecnologia capacitado para avaliar e orientar a criação dessa estrutura para um negócio. A Itix pode ajudar sua empresa a avaliar e desenvolver estruturas de TI robustas e qualificadas.
Os comentários estão desativados.